My research interest includes spatial audio, auditory scene analysis and audio (including speech & music) generation. I am currently seeking Summer 2026 research internship opportunities and PhD opportunities starting in 2027.
🔬 Research Focus
-
Comprehensive machine hearing from spatial audio and auditory neuroscience. I aim to unify spatial audio modeling with principles from auditory neuroscience so that models can jointly understand what is sounding, where it is located, and how multiple sound events are organized over time.
-
Human-centered audio evaluation as feedback for audio machine learning. I develop richer perceptual evaluation dimensions and convert human judgments of naturalness, immersion, intelligibility, and affective consistency into actionable training feedback for audio models.
-
Quantifying human-likeness in speech and singing generation to make art creation scientifically accessible. I study speech generation and singing synthesis through measurable factors of perceived human-likeness, with the goal of deconstructing seemingly intangible artistic creativity into controllable, reproducible, and accessible scientific practice.
My research is also grounded in practical experience in vocal performance, voice acting, and virtual singer tuning, which helps connect model objectives with real creative workflows. If your interests align with these directions, I would be very glad to connect and explore potential collaboration.
🔥 News
- 2026.03: 🎉🎉 Paper “FLOW-HOA: Generative Joint Optimization for Ambisonics Encoding via Flow Matching” accepted to AES Convention Europe 2026!
- 2026.03: 🎉🎉 Paper “Spherical Harmonic Beamforming based Ambisonics Encoding Method in Frequency and Time Domain” accepted to the Journal of the Audio Engineering Society!
- 2025.03: 🎉🎉 Paper “SHB-AE: Spherical harmonic beamforming based Ambisonics encoding and upscaling method for smartphone microphone array” accepted to the 158th Audio Engineering Society Convention proceedings!
- 2024.12: 🎉🎉 Paper “TA-V2A: Textually Assisted Video-to-Audio Generation” accepted to ICASSP 2025!
📝 Publications
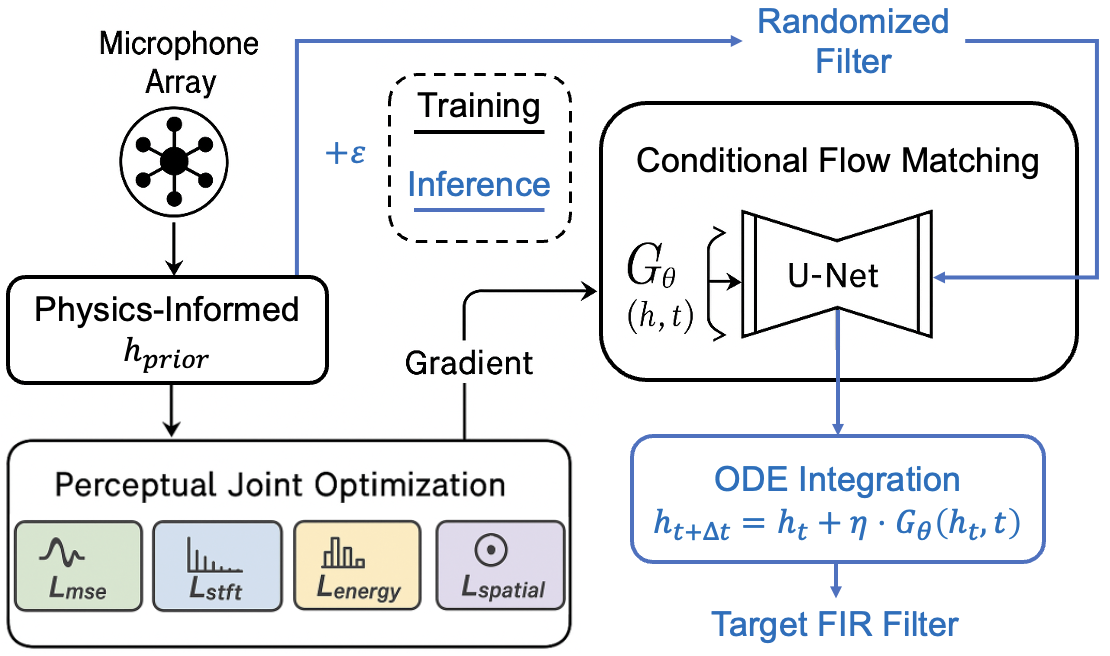
FLOW-HOA: Generative Joint Optimization for Ambisonics Encoding via Flow Matching
Yuhuan You, Yufan Qian, Tianshu Qu, Bin Wang, Xueyang Lv
Flow-HOA formulates HOA FIR filter design as a generative joint optimization problem, using conditional flow matching to refine a physics-informed prior under a composite perceptual objective spanning waveform, spectral, energy, and spatial fidelity. On a real sparse smartphone array, it surpasses the analytical ASM baseline in both objective signal/spatial metrics and subjective sound quality, showing that learned filter synthesis can reduce artifacts while preserving spatial accuracy.
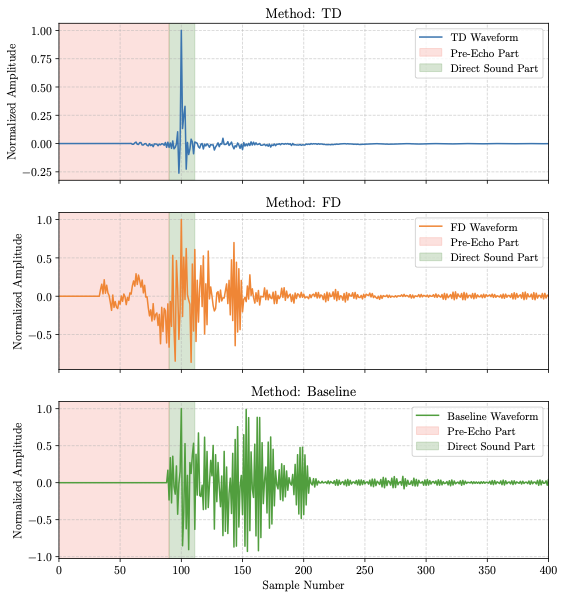
Spherical Harmonic Beamforming based Ambisonics Encoding Method in Frequency and Time Domain
Yuhuan You, Yufan Qian, Tianshu Qu, Bin Wang, Xueyang Lv
This paper generalizes SHB-AE into a unified signal-independent framework that reformulates Ambisonics encoding as beamforming and develops both a frequency-domain design with high-frequency compensation and a broadband time-domain FIR design. Compared with the earlier AES proceedings paper, this JAES version moves beyond the initial upscaling demonstration to provide a clearer FD/TD methodological split and substantially more comprehensive objective and subjective robustness evaluations on a real smartphone array.
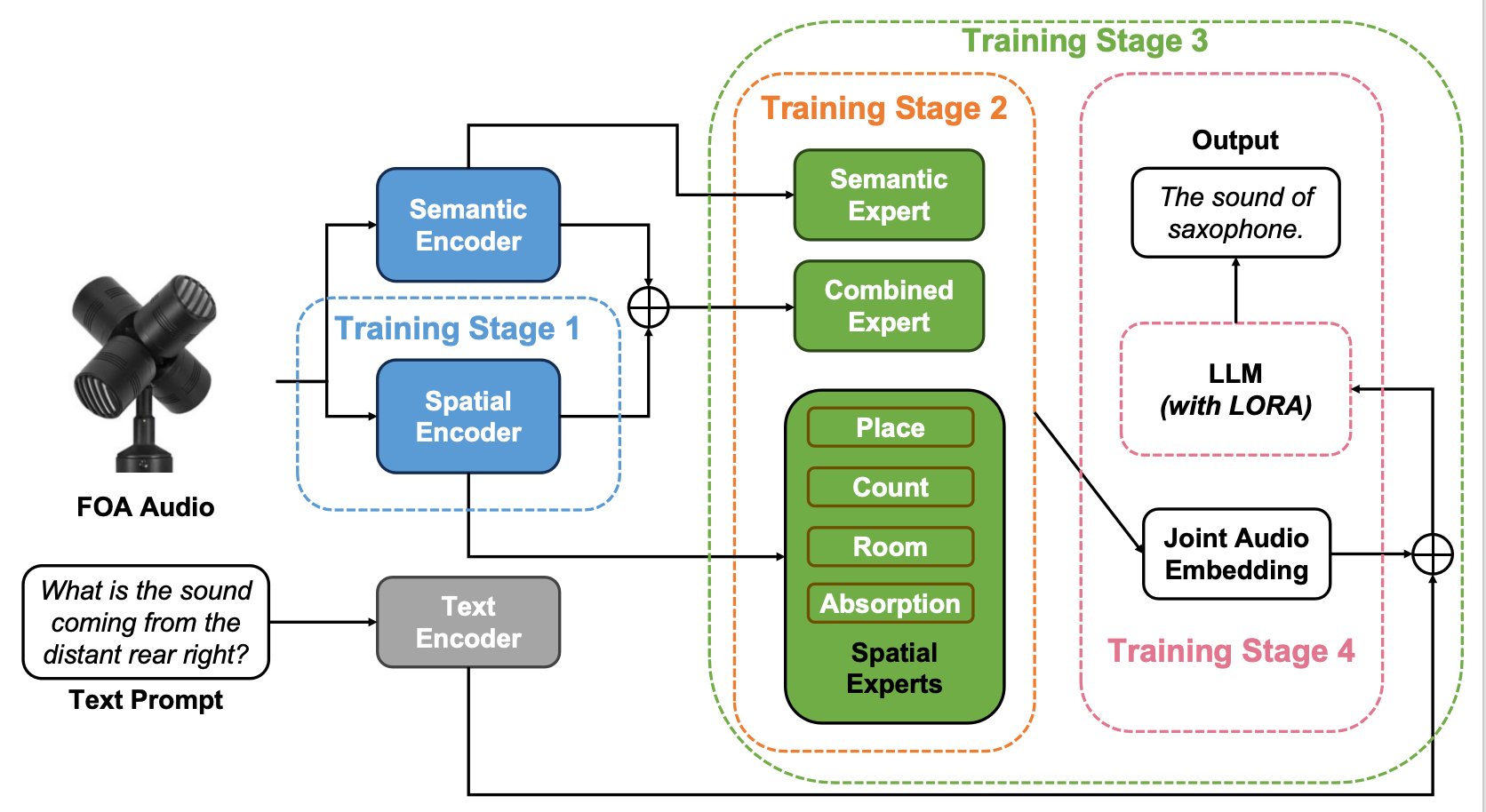
The World is Not Mono: Enabling Spatial Understanding in Large Audio-Language Models
Yuhuan You, Lai Wei, Xihong Wu, Tianshu Qu
This work formulates a hierarchical audio scene analysis pipeline that extends large audio-language models from mono recognition to spatial reasoning in complex acoustic scenes. It contributes a scalable FOA simulation pipeline, a spatial-aware model design with progressive training, and a dedicated benchmark that jointly evaluates perception, relational integration, and reasoning.
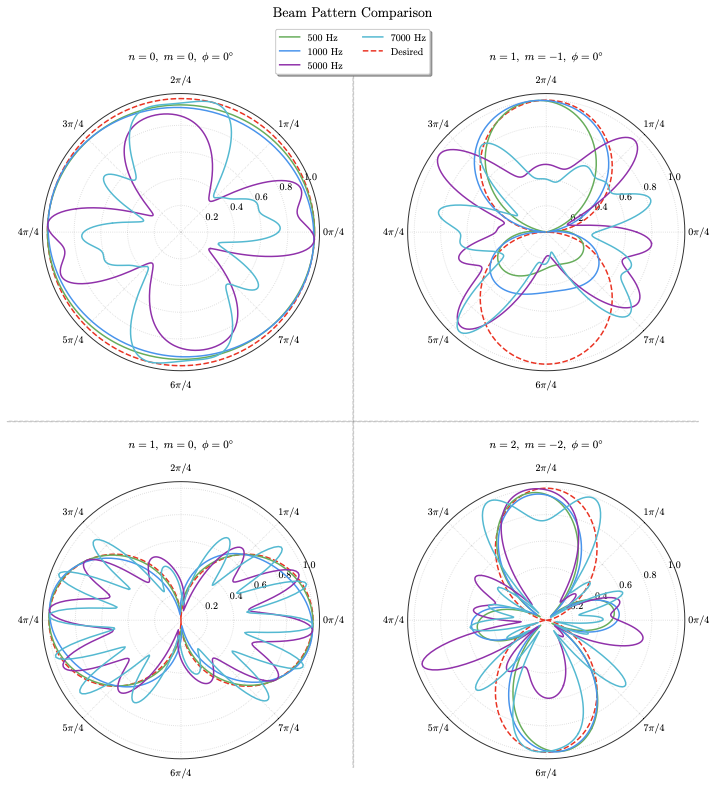
Yuhuan You, Yufan Qian, Tianshu Qu, Bin Wang, Xueyang Lv
This earlier AES proceedings paper introduced the core SHB-AE idea: using spherical-harmonic beamforming to enable Ambisonics encoding and order upscaling with a sparse, irregular smartphone microphone array. It established the feasibility of the approach under noisy and reverberant conditions, laying the foundation for the later JAES extension with unified frequency- and time-domain formulations and fuller evaluations.
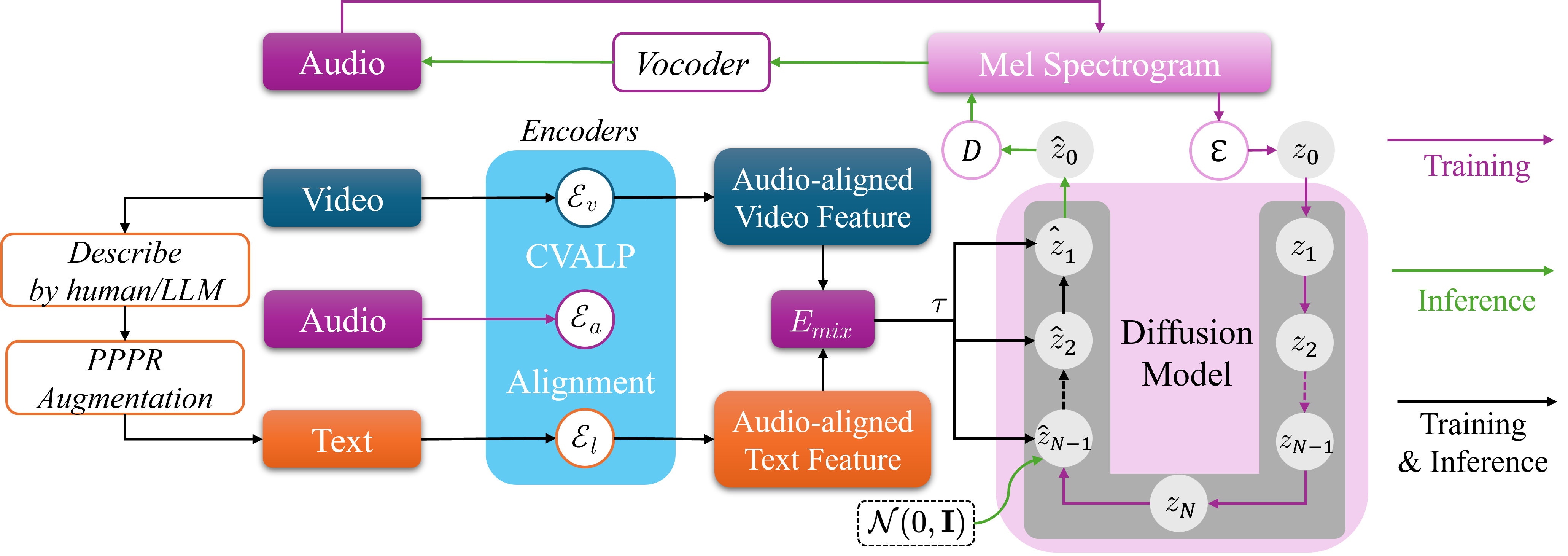
TA-V2A: Textually Assisted Video-to-Audio Generation
Yuhuan You, Xihong Wu, Tianshu Qu
TA-V2A introduces a textually assisted V2A framework that aligns video, audio, and language features through contrastive pretraining and latent feature mixing. It further improves controllability and semantic-temporal coherence by combining LLM-generated prompts, prompt refinement, and guided latent diffusion during inference.
🎖 Honors and Awards
- 2025.09 Graduate Special Academic Scholarship, Peking University
- 2020.09 Mingde Scholarship, Peking University
- 2020.09 Freshman First Class Scholarship, Peking University
- 2020.07 First Place in Hunan Province College Entrance Examination (Science)
📖 Educations
- 2024.09 - 2027.07, pursuing a master’s degree in the School of Intelligence at Peking University, with a research focus on hearing, speech, and music.
- 2020.09 - 2024.07, graduated summa cum laude from Yuanpei College, Peking University with a Bachelor’s degree in Intelligent Science and Technology, and obtained an honorary degree as a member of the Turing Class.
💻 Internships
- 2026.01 - now, intern at Alibaba Tongyi Lab, Qwen-Omni Team.